哈希表基础总结
哈希表
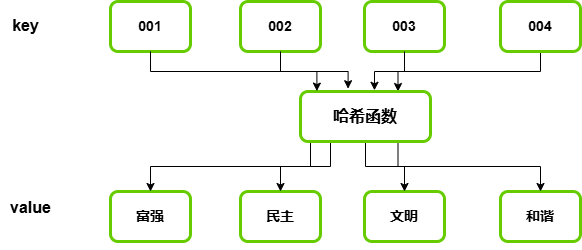
哈希表(hash table)又称作散列表,它是基于键值对(key-value pair)存储和访问数据的一种非线性数据结构。
哈希表通过哈希函数将键(key)映射到特定位置来实现对数据的快速存取与访问。
哈希表虽然只要知道键通过哈希函数就可以找到值,但是在哈希表内通常同时存储着键和值。 其主要原因是当出现哈希冲突(hash collision)时需要通过键来确定多个值具体属于哪个键。
可以用函数对应关系理解 $f(key) = address$, $array[address] = value$。
| 访问查询 | $O(1)$ |
|---|---|
| 添加元素 | $O(1)$ |
| 删除元素 | $O(1)$ |
哈希表的实现
STL中哈希表的使用
在cpp中哈希表通常是用unordered_map实现
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main(){
//初始化
unordered_map<string, int> hashmap;
unordered_map<string, int> hashtable =
{
{"num1", 1},
{"num2", 2},
{"num3", 3}
};
//访问
hashtable["num3"];
hashtable["num3"] = 1;
hashtable.at("num3");
//插入
hashmap.insert({"key", 123});
hashmap.emplace("key2", 1234);//无条件更新
hashmap.try_emplace("key2", 1234);//如果键存在则不会更新
//删除
hashmap.erase("key2");
hashmap.erase(hashmap.begin());
hashmap.clear(); //清空容器
//查找
auto it = hashtable.find("num1");
if (it != hashtable.end()){ //存在则返回所在位置迭代器,否则返回尾后迭代器
cout<<it->first<<" "<<it->second;
}
if(hashtable.count("num2") == 0){
return false;
}
bool exists = hashmap.contains("num3");
//其他操作
auto isempty = hashmap.empty();
hashmap.size();
return 0;
}
基于数组的简单实现
此处只是简单实现,为方便计算hash值key规定为int型。
对于哈希表来说哈希函数可以是其核心所在,因此哈希函数的设计尤为重要,常见的哈希函数有以下几种:
- 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即$hash(k)=k$或$hash(k)=a⋅k+b$,其中$a,b$为常数(这种散列函数叫做自身函数)
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即$hash(k)=k\ mod\ p$, $ p≤m$。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生冲突。
struct Pair{
public:
string value;
int key;
Pair(int key, string val) {
this->key = key;
this->value = val;
}
};
class hashtable{
private:
vector<Pair*> buckets;
public:
hashtable(){
buckets = vector<Pair*>(100);//申请大小为100的空间
}
~hashtable(){
for(const auto& bucket:buckets){
delete bucket;
}
buckets.clear();
}
int hashFunction(int key){
//哈希函数
int index = key % buckets.size(); //对key取模后作为下标索引便于访问键值对
return index;
}
void insert(int key, string val){
int index = hashFunction(key);
Pair* pair = new Pair(key, val);
buckets[index] = pair;
}
string search(int key){
int index = hashFunction(key);
//如果不为空,且key值相等返回value
if (buckets[index] != nullptr && buckets[index]->key == key) {
return buckets[index]->value;
}
return "";
}
void remove(int key){
int index = hashFunction(key);
delete buckets[index];
buckets[index] = nullptr;
}
void print(){
for(const auto& bucket:buckets){
if(bucket != nullptr){
cout<<bucket->key<<" "<<bucket->value<<endl;
}
}
}
};
可能你会有疑问,如果我输入的是相同的key值,那哈希函数计算出的index岂不是相同了吗?
又或者我存入的数据很多超过了预先申请的桶大小该怎么办,如果它能够自动扩容,那么因为容器大小发生了变化哈希函数的计算方式又会变化,这可能又会引发冲突。
哈希冲突
哈希冲突(hash collision)发生的原因是因为我们输入的内容要远远大于输出的内容,我们有无限的输入通过哈希函数转换成一个固定长度的索引,因此发生哈希冲突是不可避免的。
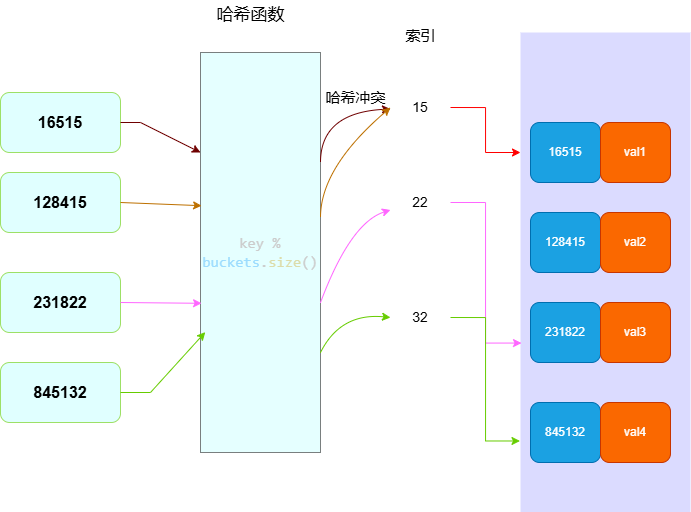
从图中我们可以猜想,如果桶的数量越大那么发生冲突的概率越低,于是我们可以通过扩容来降低哈希冲突的概率。
于是我们引入了负荷因子(load factor)用它来衡量哈希表的冲突程度。 $$ (负荷因子)α = 哈希表元素数 / 桶容量 $$ 一般 选择$α$为0.7~0.8作为触发扩容的条件。
哈希冲突的常见几种解决方法 为 开放地址法 、链式探测法和多次哈希法。