Redis 数据结构
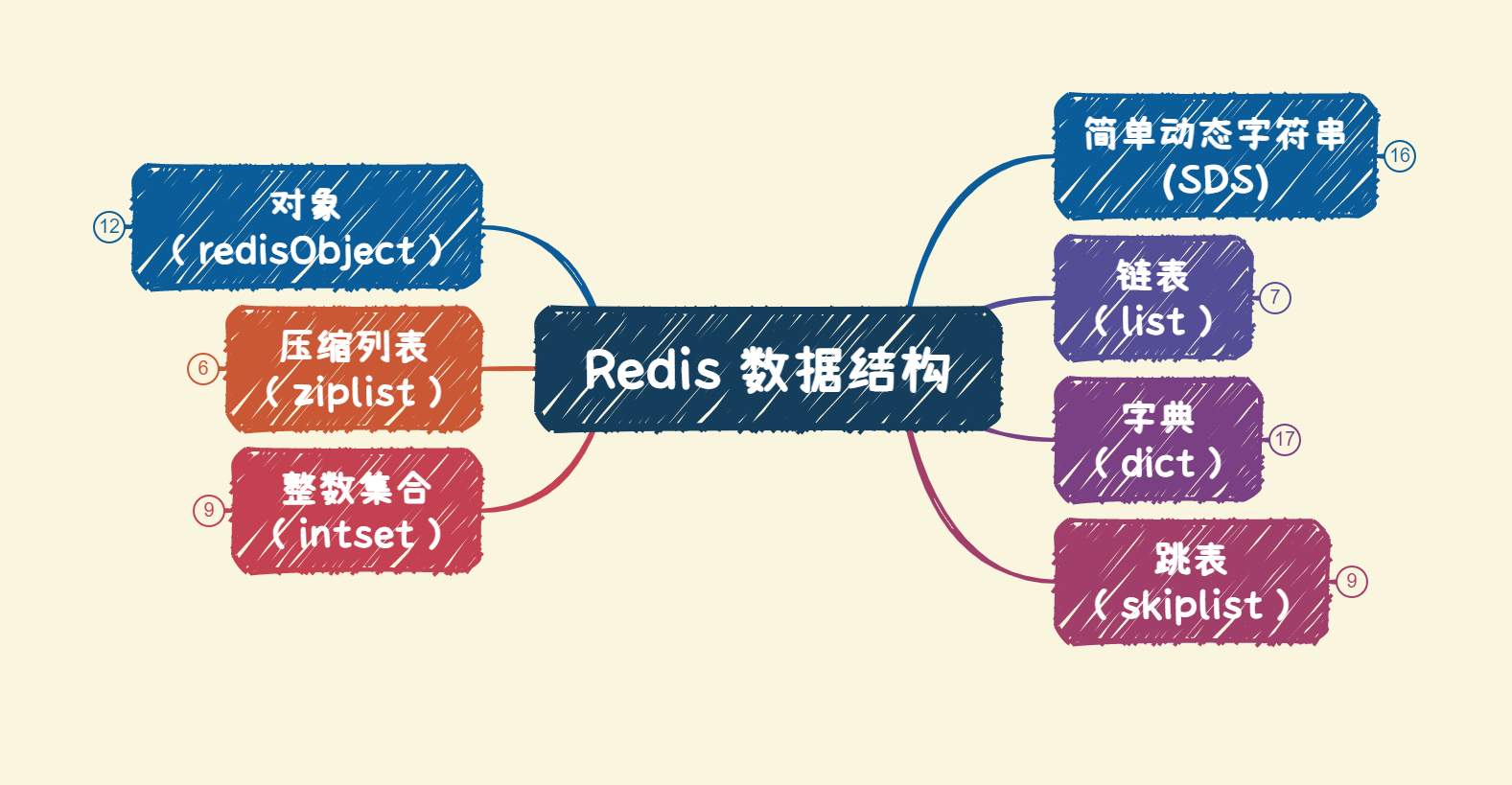
SDS

O(1) 获取长度
- SDS 在len属性保存了 SDS的长度所以无需遍历即可获得当前长度
- C 字符串不记录自身的长度信息, 为获取字符串的长度, 必须遍历整个字符串, 直到遇到代表字符串结尾的空字符为止,
O(N).
杜绝缓冲区溢出
- SDS 通过
len记录长度 和 自动扩容机制在修改时保证了当前有足够的缓冲区. - C 字符串 不检查空间 而且仅通过
\0判断结尾
空间预分配 & 惰性空间
- 空间预分配: 当需要进行空间扩容时 不仅会分配必要的空间 还会分配额外的空间.
- 惰性空间: 当SDS 缩短保存字符串时 程序不立即重新分配缩短后的字节,而是用
free记录,等待之后使用.
| 特性 | C 字符串 | SDS(Simple Dynamic String) |
|---|---|---|
| 获取字符串长度的时间复杂度 | O(N)必须遍历整个字符串直到遇到 \0 |
O(1)长度直接存储在 len 字段中,API 自动维护 |
| 缓冲区溢出风险 | 高操作函数(如 strcat)不检查目标缓冲区大小,易越界写入 |
无所有修改 API(如 sdscat)先检查空间,自动扩容后再操作 |
| 内存重分配频率 | 每次修改都需重分配增长需 realloc 防溢出,缩减需 realloc 防内存泄漏 |
大幅减少通过 空间预分配(增长时多分配)和 惰性空间释放(缩短时不立即释放)优化,避免频繁 malloc/realloc |
| 二进制安全性 | 不安全字符串中间不能含 \0,否则被截断;仅适合文本 |
安全可存储任意字节(包括 \0),数据原样存取,支持图片、音频等二进制数据 |
- SDS 的结构(简化):
struct sdshdr {
int len; // 已使用字节数(字符串长度)
int free;// 未使用字节数
char buf[];// 实际字符存储区(以 \0 结尾,但内容可含 \0)
}
链表
特点
- 实现为 双端无环链表。
- 支持 多态(通过
dup/free/match函数指针)。 - 用于:List 键、客户端列表、慢查询、发布订阅等。
结构
typedef struct listNode {
struct listNode *prev, *next;
void *value;
} listNode;
typedef struct list {
listNode *head, *tail;
unsigned long len;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
} list;
字典
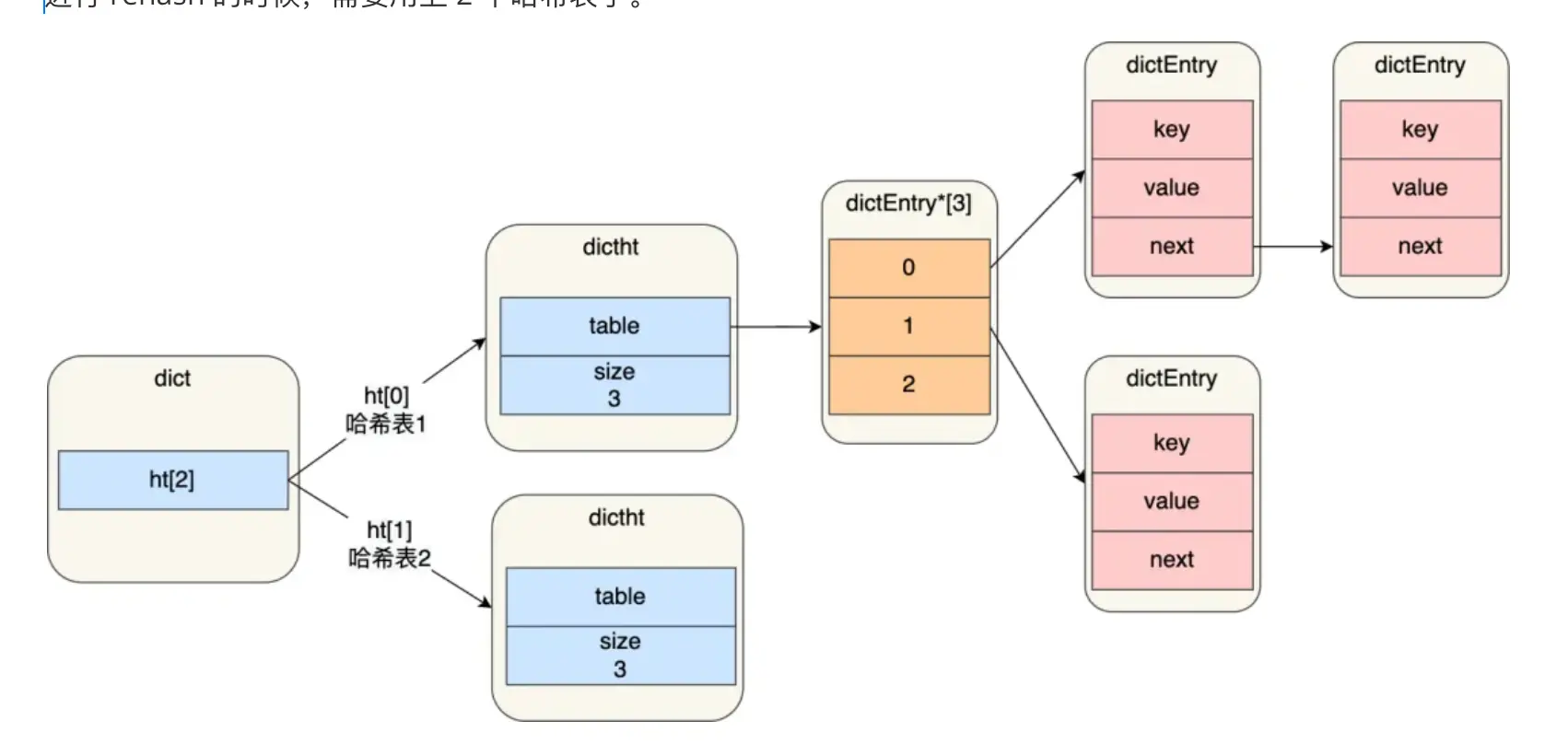
底层结构
Redis 字典由 两个哈希表(ht[0] 和 ht[1])组成:
typedef struct dict {
dictht ht[2]; // ht[0]: 主表;ht[1]: rehash 时的新表
int rehashidx; // rehash 进度,-1 表示未进行
} dict;
- 每个哈希表(
dictht)是一个 数组 + 单向链表:- 数组元素为桶(bucket);
- 桶内冲突通过 链地址法(单向链表)解决;
- 节点类型为
dictEntry,含key、value和next指针。
扩容与缩容机制
1. 触发条件(基于负载因子)
负载因子 = ht[0].used / ht[0].size
| 场景 | 触发 rehash 条件 |
|---|---|
| 无 BGSAVE / BGREWRITEAOF | 负载因子 ≥ 1 → 扩容 |
| 有 BGSAVE / BGREWRITEAOF | 负载因子 ≥ 5 → 才扩容(避免 fork 内存翻倍) |
| 缩容 | 负载因子 < 0.1 且表足够大 |
2. 扩容过程(渐进式 rehash)
-
分配
ht[1]:- 扩容:
size = 第一个 ≥ ht[0].used * 2 的 2 的幂 - 缩容:
size = 第一个 ≥ ht[0].used 的 2 的幂
- 扩容:
-
设置
rehashidx = 0,开始 rehash。 -
每次字典操作(GET/SET/DEL)时:
- 顺带迁移
ht[0][rehashidx]整个桶 到ht[1]; rehashidx++;- 新增操作只写入
ht[1]; - 查找/删除需查两个表(因数据分散在两表中)。
- 顺带迁移
-
迁移完成:
- 释放
ht[0]; ht[1] → ht[0];rehashidx = -1。
- 释放
三、关键特点与代价
优点
- 无阻塞:rehash 分摊到每次操作,主线程不卡顿;
- 数据安全:双表共存期间,读写正确;
- 自动适应:根据负载动态扩缩容。
缺点
- 内存占用翻倍:rehash 期间
ht[0]和ht[1]同时存在; - 冷数据 rehash 延迟:长期无访问的字典可能迟迟无法完成 rehash;
- Redis 通过
serverCron定时任务主动推进缓解此问题。
- Redis 通过
跳表

底层结构
跳表本质上就是多层级链表,不同层级保存着随机跨度的后驱节点的指针,用来快速查找.
节点:
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值,用于排序
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
//跨度
unsigned long span;
} level[];
} zskiplistNode;
顶层结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾指针(O(1) 访问)
unsigned long length; // 节点总数(O(1) 获取长度)
int level; // 当前跳表最大层数(不含头节点)
} zskiplist;
header是一个 特殊的头节点,不存实际数据(ele = NULL,score = 0),但有完整的level[]数组(如 32 层或 64 层)。tail指向最后一个真实数据节点(用于ZREVRANGE等反向操作)。level是 所有数据节点中的最大层数(头节点层数不计入)。
创建过程
Redis在创建头节点时如果层高最大限制是 32,那么在创建跳表「头节点」的时候,就会直接创建 32 层高的头节点.
在创建新节点时会在 [0, 1] 随机取值,如果小于 0.25 则会增加层高,继续取值,直到值大于 0.25.
Redis为什么使用跳表而不是用B+树?
Redis 是内存数据库,跳表在实现简单性、写入性能、内存访问模式等方面的综合优势,使其成为更合适的选择。
| 维度 | 跳表优势 | B+ 树劣势 |
| 内存访问 | 符合CPU缓存局部性,指针跳转更高效 | 节点结构复杂,缓存不友好 |
| 实现复杂度 | 代码简洁,无复杂平衡操作 | 节点分裂/合并逻辑复杂,代码量大 |
| 写入性能 | 插入/删除仅需调整局部指针 | 插入可能触发递归节点分裂,成本高 |
| 内存占用 | 结构紧凑,无内部碎片 | 节点预分配可能浪费内存 |
Redis 选择使用跳表(Skip List)而不是 B+ 树来实现有序集合(Sorted Set)等数据结构,是经过多方面权衡后的结果。以下是详细的原因分析:
1、内存结构与访问模式的差异
B+ 树的特性
- 磁盘友好:B+ 树的设计目标是优化磁盘I/O,通过减少树的高度来降低磁盘寻道次数(例如,一个3层的B+树可以管理数百万数据)。
- 节点填充率高:每个节点存储多个键值(Page/Block),适合批量读写。
- 范围查询高效:叶子节点形成有序链表,范围查询(如
ZRANGE)性能极佳。
跳表的特性
- 内存友好:跳表基于链表,通过多级索引加速查询,内存访问模式更符合CPU缓存局部性(指针跳跃更少)。
- 简单灵活:插入/删除时仅需调整局部指针,无需复杂的节点分裂与合并。
- 概率平衡:通过随机层高实现近似平衡,避免了严格的平衡约束(如红黑树的旋转)。
Redis 是内存数据库,数据完全存储在内存中,不需要优化磁盘I/O,因此 B+ 树的磁盘友好特性对 Redis 意义不大。而跳表的内存访问模式更优,更适合高频的内存操作。
2、实现复杂度的对比
B+ 树的实现复杂度:
- 节点分裂与合并:插入/删除时可能触发节点分裂或合并,需要复杂的再平衡逻辑。
- 锁竞争:在并发环境下,B+ 树的锁粒度较粗(如页锁),容易成为性能瓶颈。
- 代码复杂度:B+ 树的实现需要处理大量边界条件(如最小填充因子、兄弟节点借用等)。
跳表的实现复杂度:
- 无再平衡操作:插入时只需随机生成层高,删除时直接移除节点并调整指针。
- 细粒度锁或无锁:跳表可以通过分段锁或无锁结构(如 CAS)实现高效并发。
- 代码简洁:Redis 的跳表核心代码仅需约 200 行(B+ 树实现通常需要数千行)。
对于 Redis 这种追求高性能和代码简洁性的项目,跳表的低实现复杂度更具吸引力,Redis作者Antirez曾表示,跳表的实现复杂度远低于平衡树,且性能相近,是更优选择。
3、性能对比
查询性能
- 单点查询:跳表和 B+ 树的时间复杂度均为
O(log N),但跳表的实际常数更小(内存中指针跳转比磁盘块访问快得多)。 - 范围查询:B+ 树的叶子链表在范围查询时占优,但跳表通过双向链表也能高效支持
ZRANGE操作。
写入性能
- B+ 树:插入可能触发节点分裂,涉及父节点递归更新,成本较高。
- 跳表:插入仅需修改相邻节点的指针,写入性能更优(Redis 的
ZADD操作时间复杂度为O(log N))。
实测数据:在内存中,跳表的插入速度比 B+ 树快 2-3 倍,查询速度相当。
4、内存占用
- B+ 树:每个节点需要存储多个键值和子节点指针,存在内部碎片(节点未填满时)。
- 跳表:每个节点只需存储键值、层高和多个前向指针,内存占用更紧凑。
压缩列表是怎么实现的?
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。

压缩列表在表头有三个字段:
- zlbytes,记录整个压缩列表占用对内存字节数;
- zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- zllen,记录压缩列表包含的节点数量;
- zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
在压缩列表中,如果我们要查找定位首尾元素通过表头三个字段(zllen)的长度直接定位,复杂度是 O(1)。查找其他元素时,只能逐个查找O(N) ,因此压缩列表不适合保存过多的元素。
另外,压缩列表节点(entry)的构成如下:
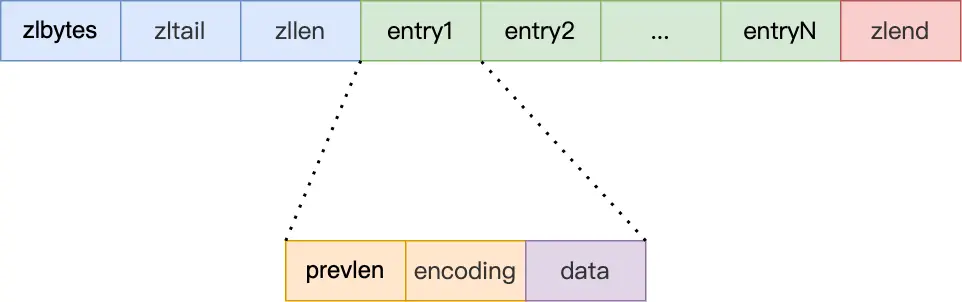
压缩列表节点包含三部分内容:
- prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
- encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
- data,记录了当前节点的实际数据,类型和长度都由 encoding 决定;
往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
压缩列表的缺点是会发生连锁更新的问题,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
所以说,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是能接受的。
虽说如此,Redis 针对压缩列表在设计上的不足,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
listpack 采用了压缩列表的很多优秀的设计,比如还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
我们先看看 listpack 结构:

listpack 头包含两个属性,分别记录了 listpack 总字节数和元素数量,然后 listpack 末尾也有个结尾标识。图中的 listpack entry 就是 listpack 的节点了。
每个 listpack 节点结构如下:
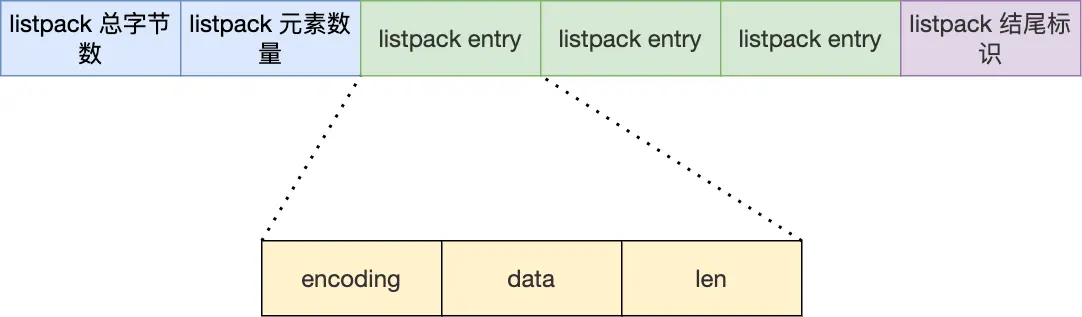
主要包含三个方面内容:
- encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
- data,实际存放的数据;
- len,encoding+data的总长度;
可以看到,listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。