Redis 生产问题
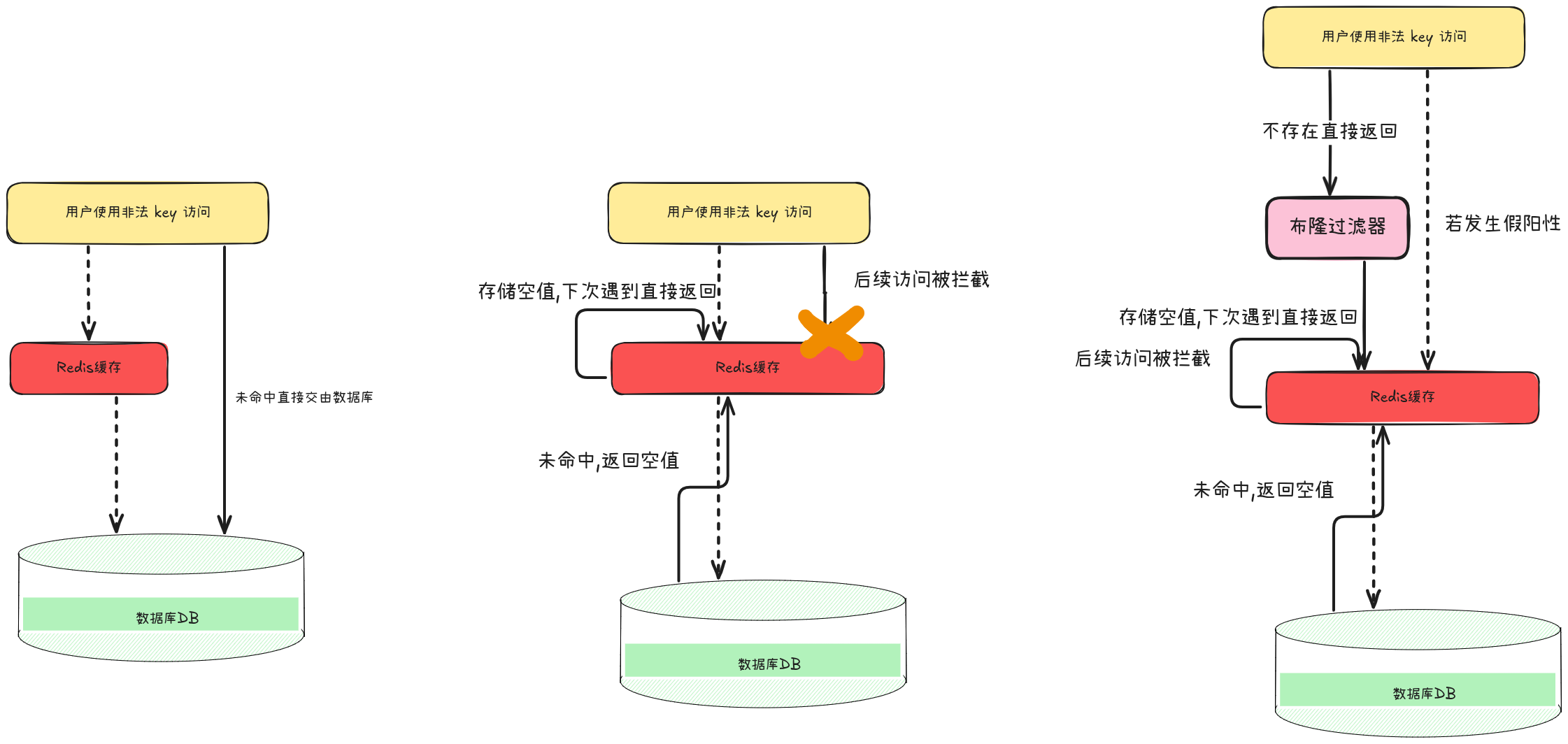
缓存穿透
指使用非法 key 进行请求, 这个 key 不存在于 Redis 缓存和数据库中. 导致数据库一直忙于处理非法 key 的查询请求.
1. 缓存空值
使用 Redis 缓存空值,将不存在的 key 加入缓存,之后直接在 Redis 被拦截.
- 优点 :实现简单,成本低.
- 缺点 : 大量不同非法 key 访问会占用大量 redis 缓存.
- 改进: 给空值 key 设置较短的过期时间 或者加入布隆过滤器.
2. 布隆过滤器
使用布隆过滤器首先判断当前请求的数据是否存在, 若不存在直接拦截, “存在"后继续交由 redis 进行.
优点: bloomfilter 使用了散列算法"存储”,占用空间极小,速度快.
缺点: bloomfilter 会出现假阳性,同时无法删除数据.
改进: 使用 缓存空值兜底,同时定期刷新写入真实的数据.
缓存击穿
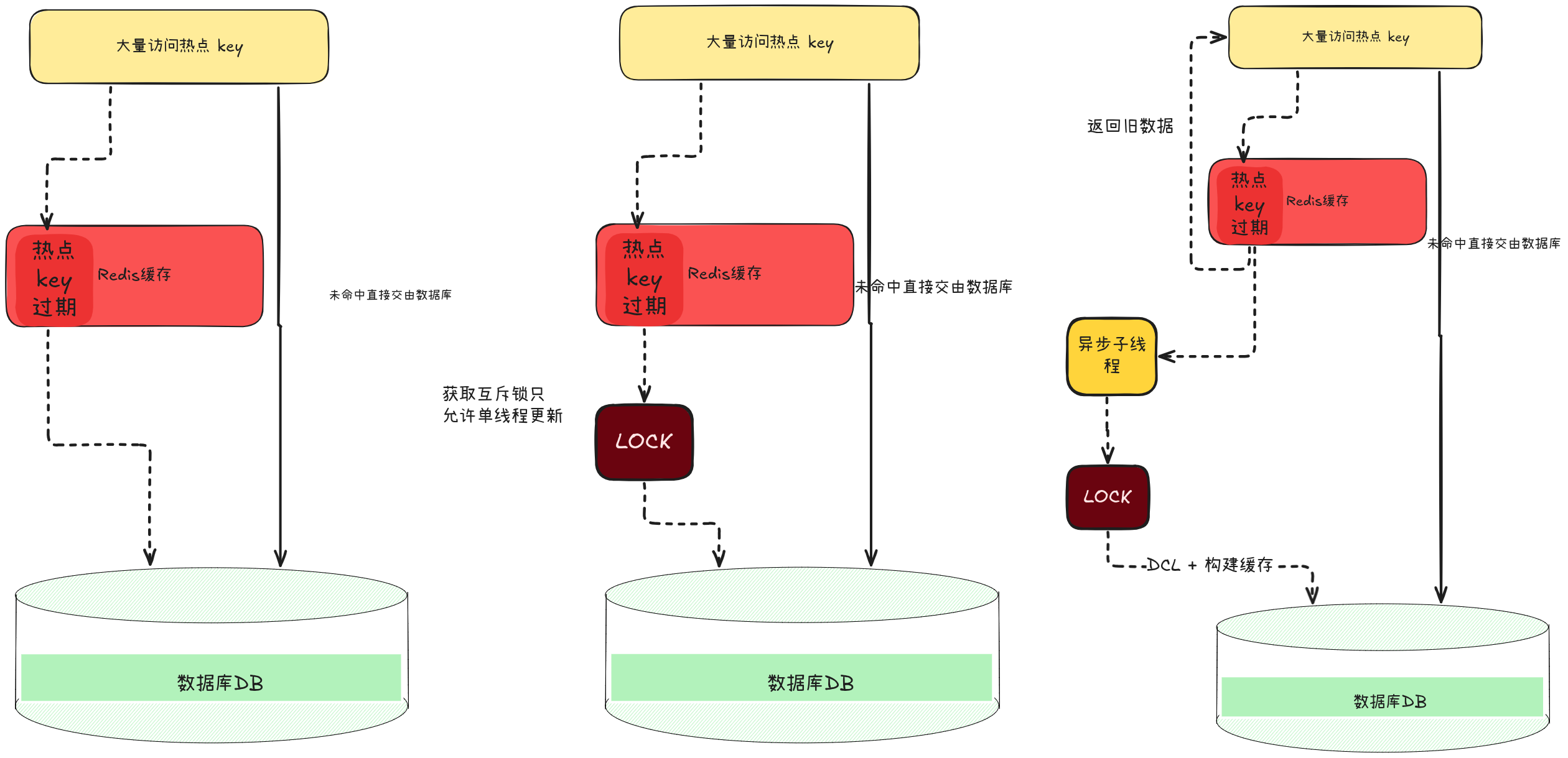
1. 分布式锁
通过加入分布式只允许一个线程同时去访问数据库进行缓存重建,其他线程等待缓存好的数据. 步骤: A. redis 缓存未命中,尝试获取锁 B. 获取锁成功,进行双重检查 C. 查询数据库 D.重新加入 Redis 缓存 (若为空则构造空值)
缺点:
- 导致大量用户被堵塞,体验较差.
- 锁竞争激烈时,性能下降
- 如果锁未正确释放(如程序崩溃),可能导致死锁
改进:
- 使用 Redis 的
SET key value NX PX milliseconds命令原子操作加锁。 - 加锁失败时,不要无限等待,可以返回“稍后再试”或“默认值”。
2.逻辑过期 + 异步更新
在非强一致性场景下,缓存数据时加入逻辑过期时间,若发生过期则先返回旧数据,同时获取分布式锁进行异步更新缓存. 步骤: A. redis 缓存命中, 但此时逻辑过期 B. 返回旧数据,同时尝试获取锁. C. 开启子线程,进行双重检查 D. 重构缓存 缺点:
- 复杂度较高, 需要维护逻辑过期字段、异步线程、锁机制
- 用户可能无法及时获取到最新数据.
- 内存占用略高,因为缓存不会真正过期,除非手动清理。
改进:
- 对缓存设置较长的过期时间,大于逻辑过期时间.
3. 缓存预热
针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
缓存雪崩
指缓存内同时出现大量 key 过期或者 Redis 奔溃重启,没有缓存任何key,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。
1. 随机过期时间
通过 在 Redis 重构缓存时在过期时间中加入随机抖动使得过期时间均匀分散,避免了大量 key 同时过期的情况.
2. Redis 集群
通过构建 Redis 主从架构+哨兵机制实现, 当主节点下线后,哨兵会自动把从节点提升为主节点. 多个节点保证了不会出现缓存全部消失的情况.
**服务降级 & 熔断
当数据库压力过大时:
- 返回默认值(如“系统繁忙,请稍后再试”)。
- 启用本地缓存(如 Caffeine)作为二级缓存。
- 使用限流(如 Sentinel、Hystrix)保护数据库。
3.预热数据