Stack 基础总结
栈
栈(Stack)属于线性数据结构,它遵循着先进后出(FILO)原则,就像是在杠铃上的杠铃片,要想拿到最开始放进去的片必须把在它之后的所有杠铃片全部弹出(pop),而每次加新片只能在末尾压入(push),通常我们把最后一个入栈元素的位置叫做`栈顶`,最先入栈的元素叫做`栈底`.
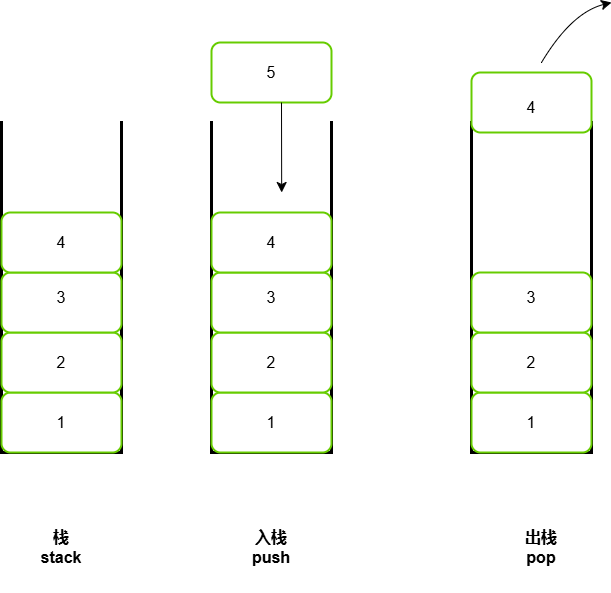
栈的实现
在CPP中有内置的栈包含在stack头文件中,但这里我们分别用数组和链表来模拟栈的基本功能。
基于数组的实现方式
class Stack{
private:
std::vector<int> st;
public:
//获取栈的大小
int getSize(){
return st.size();
}
//检查是否为空
bool isEmpty(){
return st.empty();
}
//返回栈顶元素
int peek(){
if (isEmpty()) throw std::out_of_range("栈为空");
return st.back();
}
//添加元素
void push(int val){
st.push_back(val);
}
//弹出元素
void pop(){
if (isEmpty()) throw std::out_of_range("栈为空");
st.pop_back();
}
};
基于链表的实现方式
class Stack{
private:
Node* st;
public:
Stack() : st(nullptr) {}
// 析构函数,防止内存泄漏
~Stack() {
while (!isEmpty()) {
pop();
}
}
//获取栈的大小
int getSize(){
Node* tmp = st;
int size;
for(size = 0; tmp != nullptr; size++){
tmp = tmp->next;
}
return size;
}
//检查是否为空
bool isEmpty(){
if(st == nullptr) return true;
else return false;
}
//返回栈顶元素
int peek(){
if (isEmpty()) throw std::out_of_range("栈为空");
return st->val;
}
//添加元素
void push(int val){
Node* nd = new Node(val);
nd->next = st;
st = nd;
}
//弹出元素
void pop(){
if (isEmpty()) throw std::out_of_range("栈为空");
auto tmp = st->next;
delete st;
st = tmp;
}
};
Node的详细实现详见链表,此处只简单实现。
class Node{
public:
int val;
Node* next;
Node(int value): val(value), next(nullptr) {}
}
值得注意的是此处新元素的插入与链表直接在尾部插入不同,而是在头部插入,并将新的节点作为头节点。
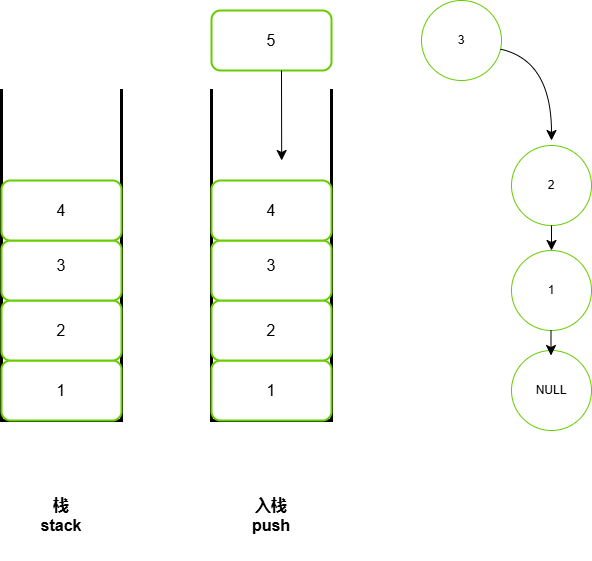
*两种实现的对比
支持操作
两种实现都支持栈定义中的各项操作。数组实现额外支持随机访问,但这已超出了栈的定义范畴,因此一般不会用到。
时间效率
在基于数组的实现中,入栈和出栈操作都在预先分配好的连续内存中进行,具有很好的缓存本地性,因此效率较高。然而,如果入栈时超出数组容量,会触发扩容机制,导致该次入栈操作的时间复杂度变为 O(n) 。
在基于链表的实现中,链表的扩容非常灵活,不存在上述数组扩容时效率降低的问题。但是,入栈操作需要初始化节点对象并修改指针,因此效率相对较低。不过,如果入栈元素本身就是节点对象,那么可以省去初始化步骤,从而提高效率。
综上所述,当入栈与出栈操作的元素是基本数据类型时,例如
int或double,我们可以得出以下结论。
- 基于数组实现的栈在触发扩容时效率会降低,但由于扩容是低频操作,因此平均效率更高。
- 基于链表实现的栈可以提供更加稳定的效率表现。
空间效率
在初始化列表时,系统会为列表分配“初始容量”,该容量可能超出实际需求;并且,扩容机制通常是按照特定倍率(例如 2 倍)进行扩容的,扩容后的容量也可能超出实际需求。因此,基于数组实现的栈可能造成一定的空间浪费。
然而,由于链表节点需要额外存储指针,因此链表节点占用的空间相对较大。
综上,我们不能简单地确定哪种实现更加节省内存,需要针对具体情况进行分析。
栈相关练习题
- 二叉树的迭代法进行前中后序遍历